Welcome to HPCDC Tutorial at SC 2017
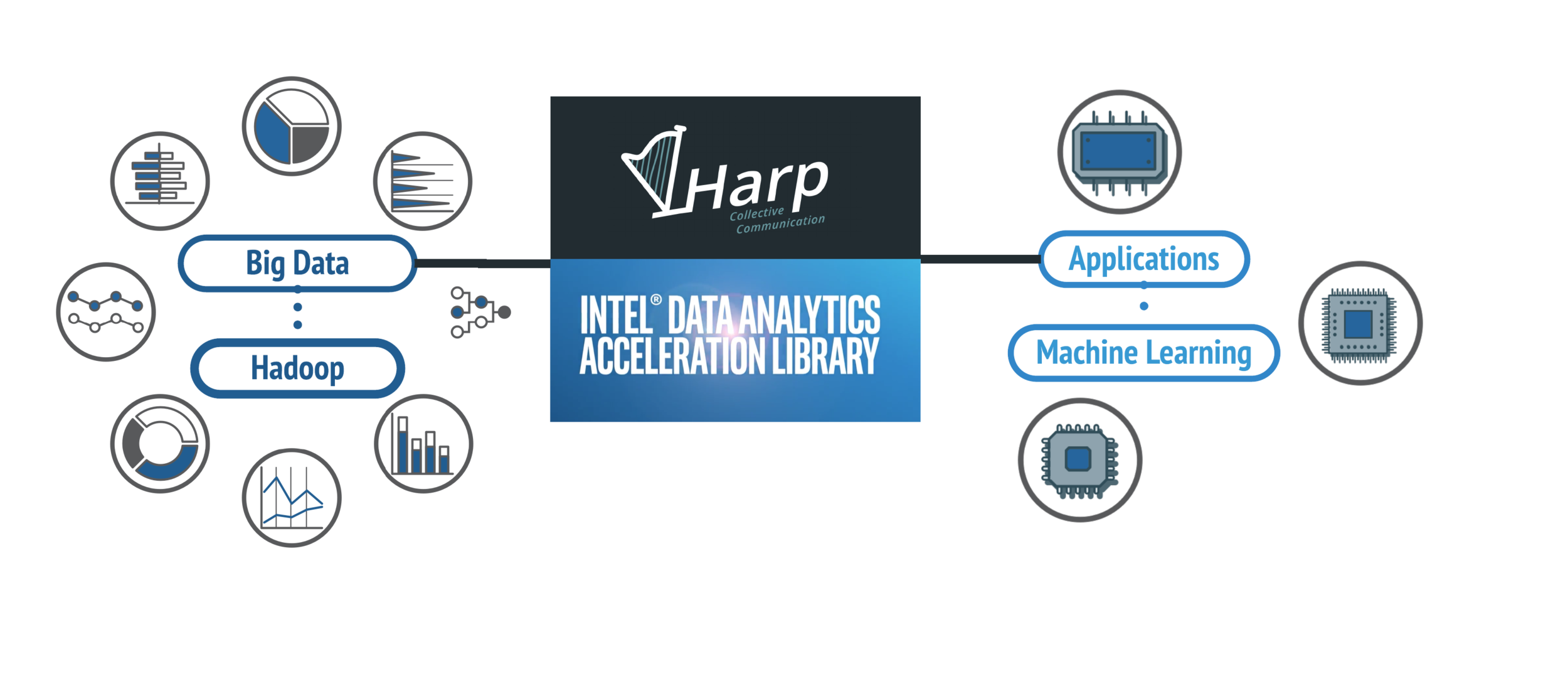
Harp-DAAL
Hands on
in collaboration with
is a high performance framework with the fastest machine learning algorithms on Intel's Xeon and Xeon Phi architectures.
See how it works
Explore algorithms
Performance

Slide deck
Home
The three key technical components giving Harp-DAAL world leading performance
Computation Model
Collective Communication
DAAL-Kernel

K-means
Linear Regression
Naive Bayes


Neural Network
MF-SGD
Algorithms
Back
Home
K-means
Home
Problem
Solution
Demo
Result

Algorithms
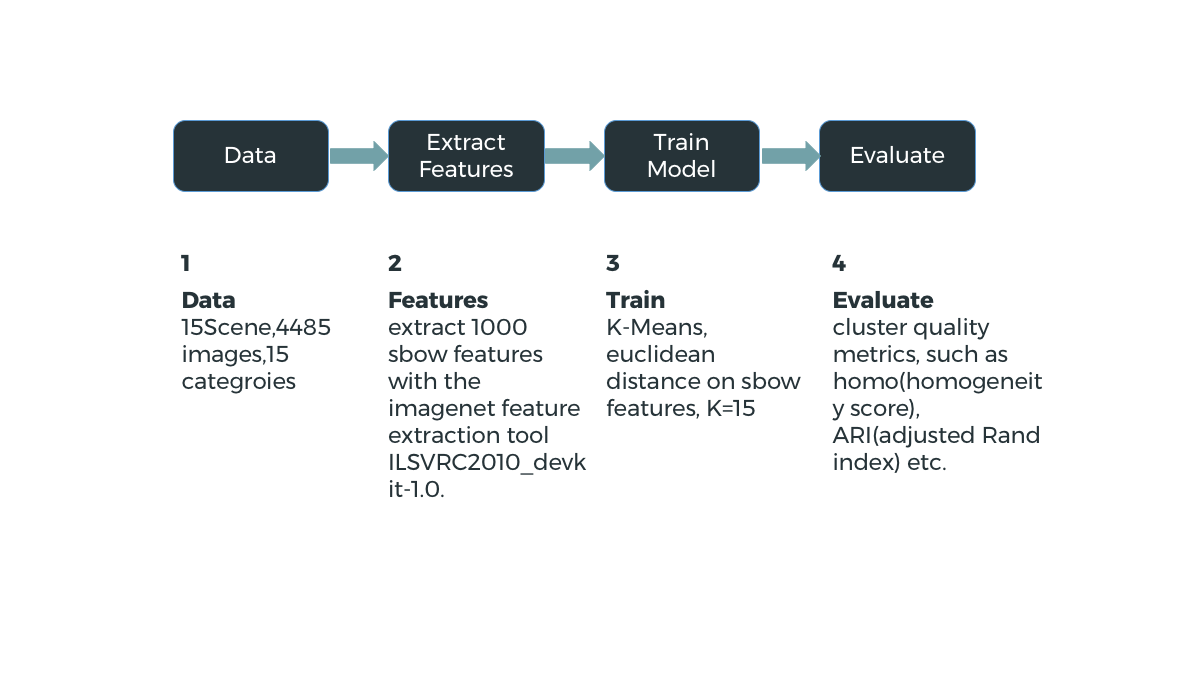
K-means
Home
Problem
Solution
Demo
Result
Algorithms
K-means
Home
Problem
Solution
Demo
Result

Algorithms
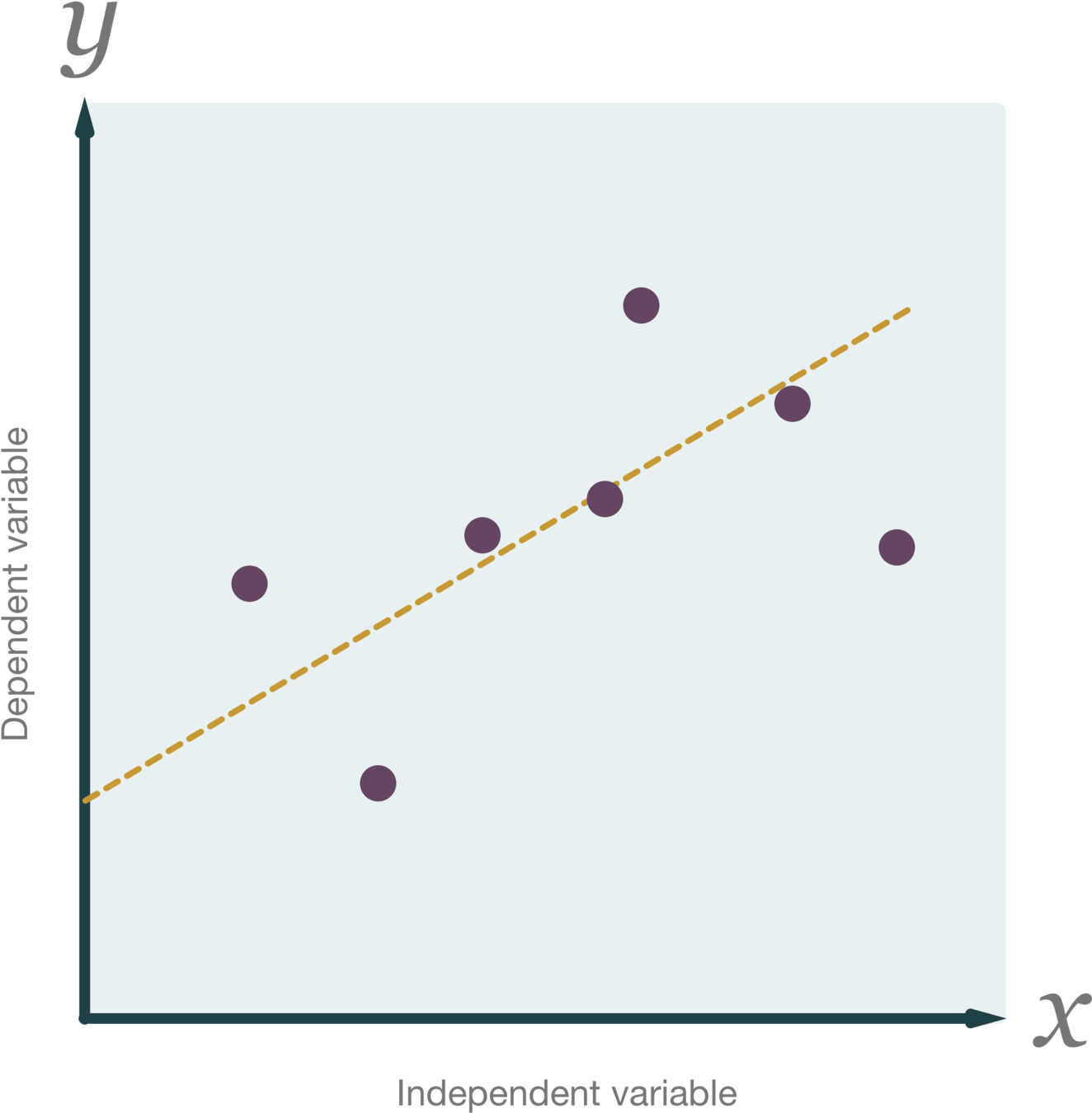
Linear Regression
Home
Problem
Solution
Demo
Result
Algorithms

Home
Problem
Solution
Demo
Result
Algorithms
Linear Regression

Home
Problem
Solution
Demo
Result
Algorithms
Linear Regression
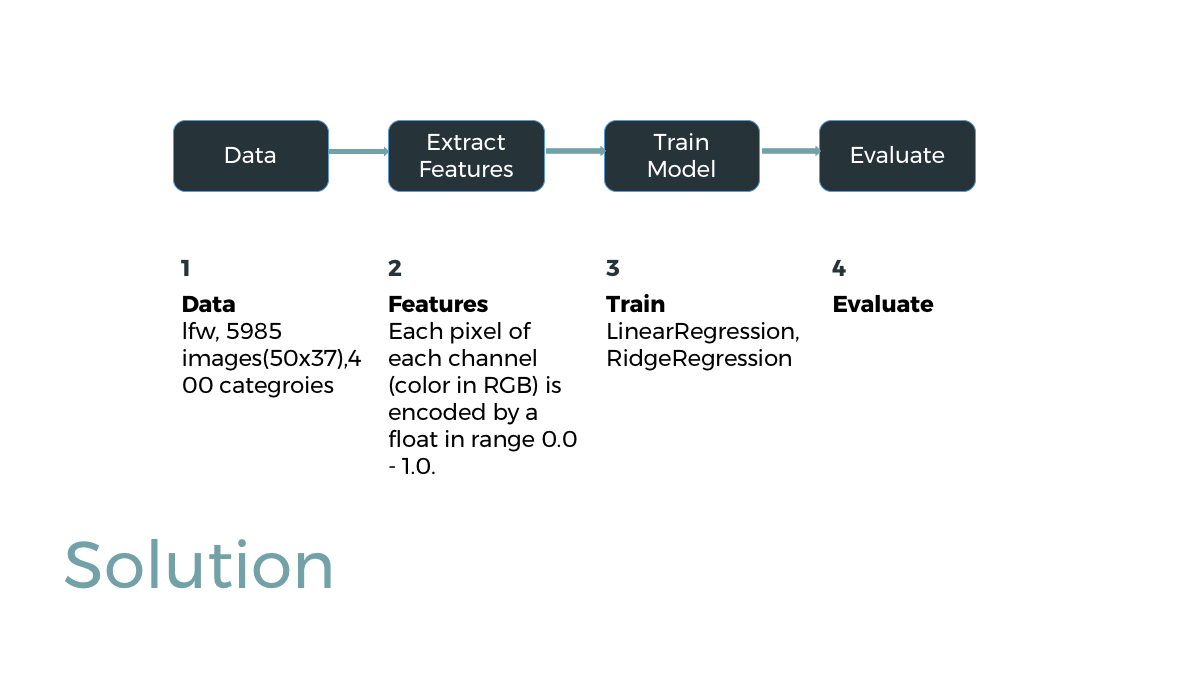
Home
Problem
Solution
Demo
Result
Algorithms
Linear Regression

Naive Bayes
Home
Problem
Solution
Demo
Result
Algorithms

Home
Problem
Solution
Demo
Result
Algorithms
Naive Bayes

Home
Problem
Solution
Demo
Result
Algorithms
Naive Bayes
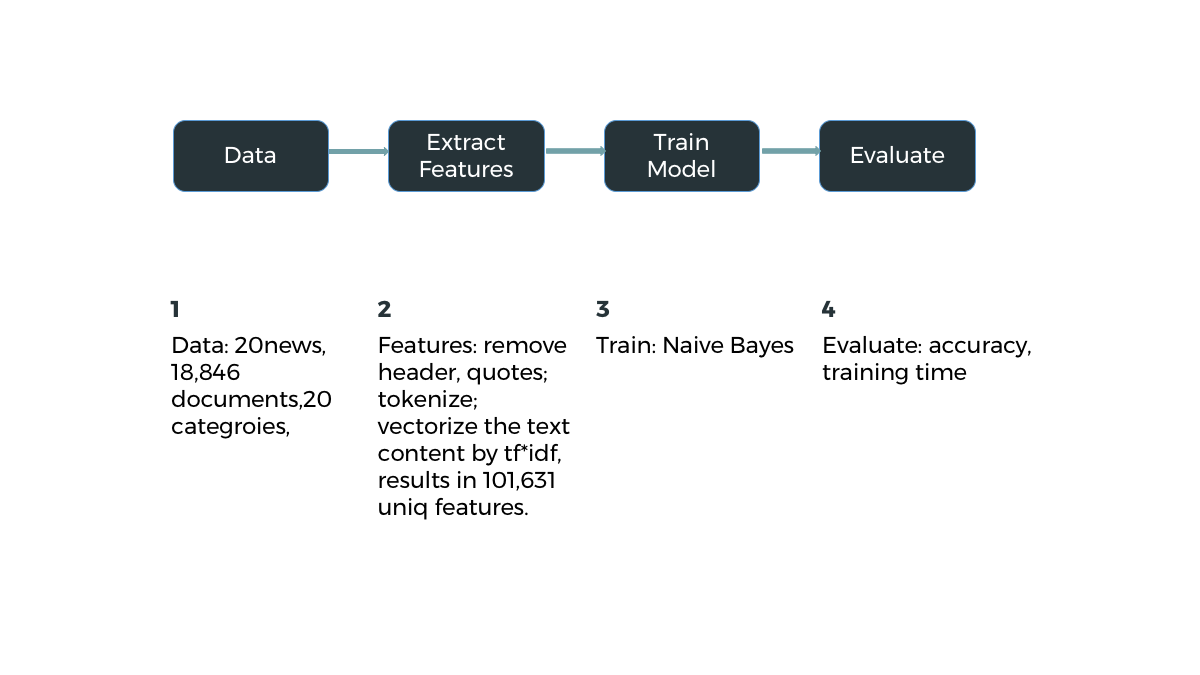
Home
Problem
Solution
Demo
Result
Algorithms
Naive Bayes
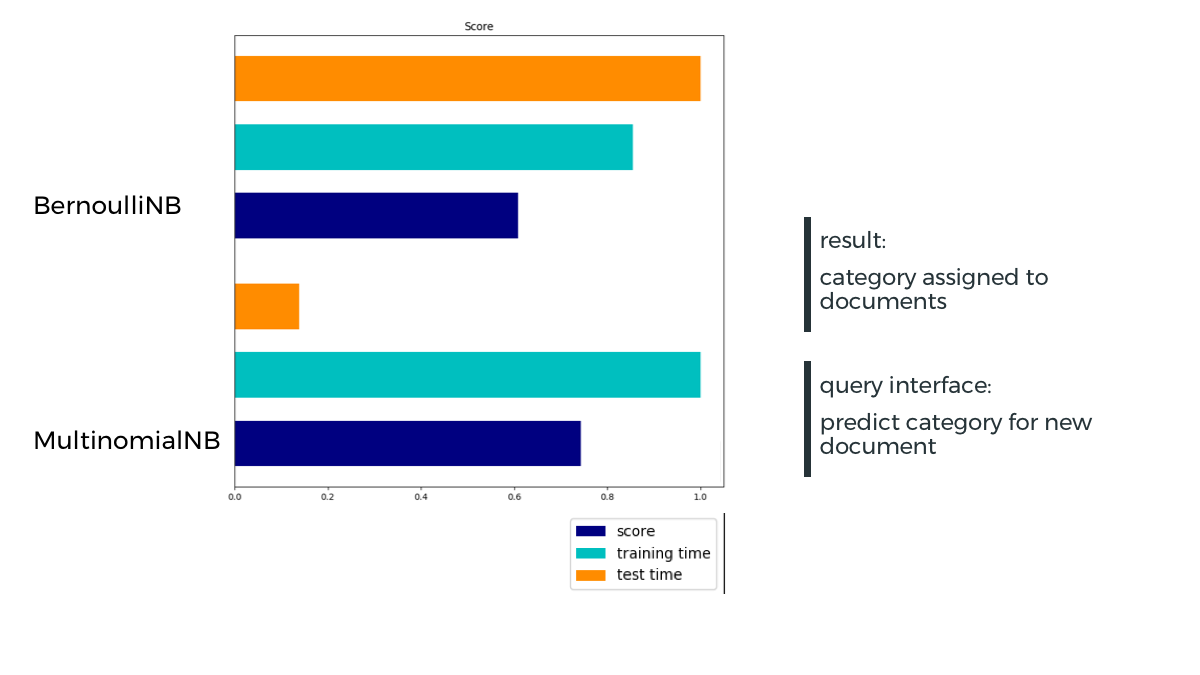
Neural Networks
Home
Problem
Solution
Demo
Result
Algorithms

Home
Problem
Solution
Demo
Result
Algorithms
Neural Networks

Home
Problem
Solution
Demo
Result
Algorithms
Neural Networks
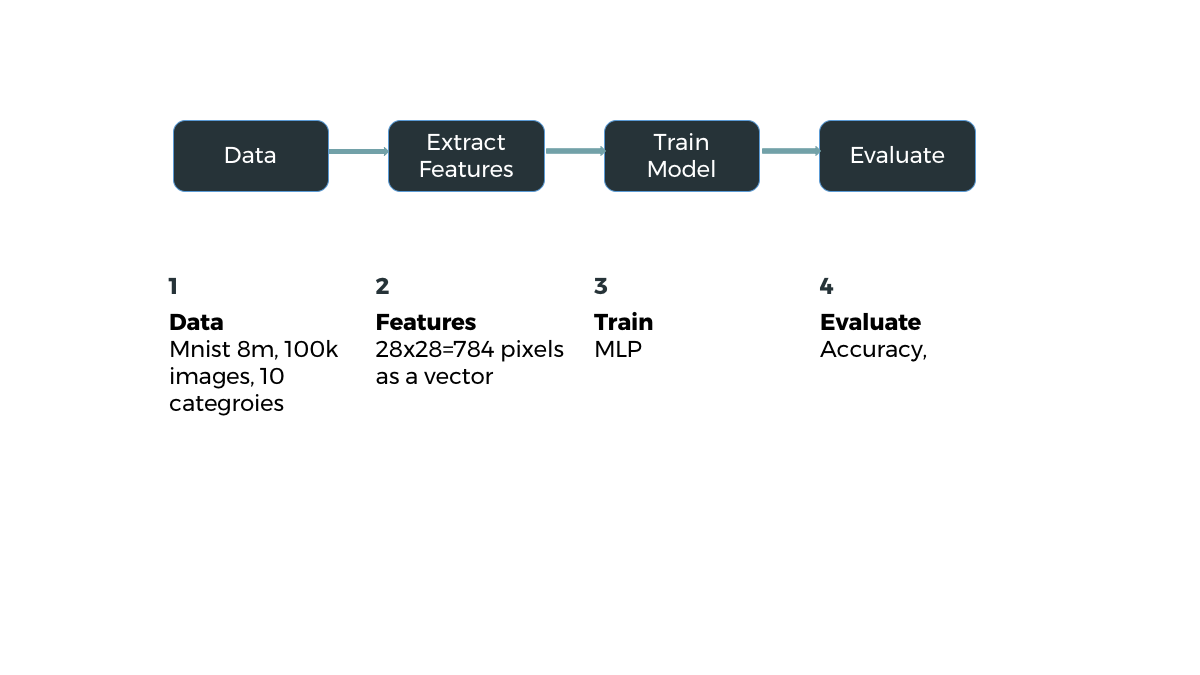
Home
Problem
Solution
Demo
Result
Algorithms
Neural Networks

Matrix Factorization-SGD
Home
Problem
Solution
Demo
Result
Algorithms

Home
Problem
Solution
Demo
Result
Algorithms
Matrix Factorization-SGD
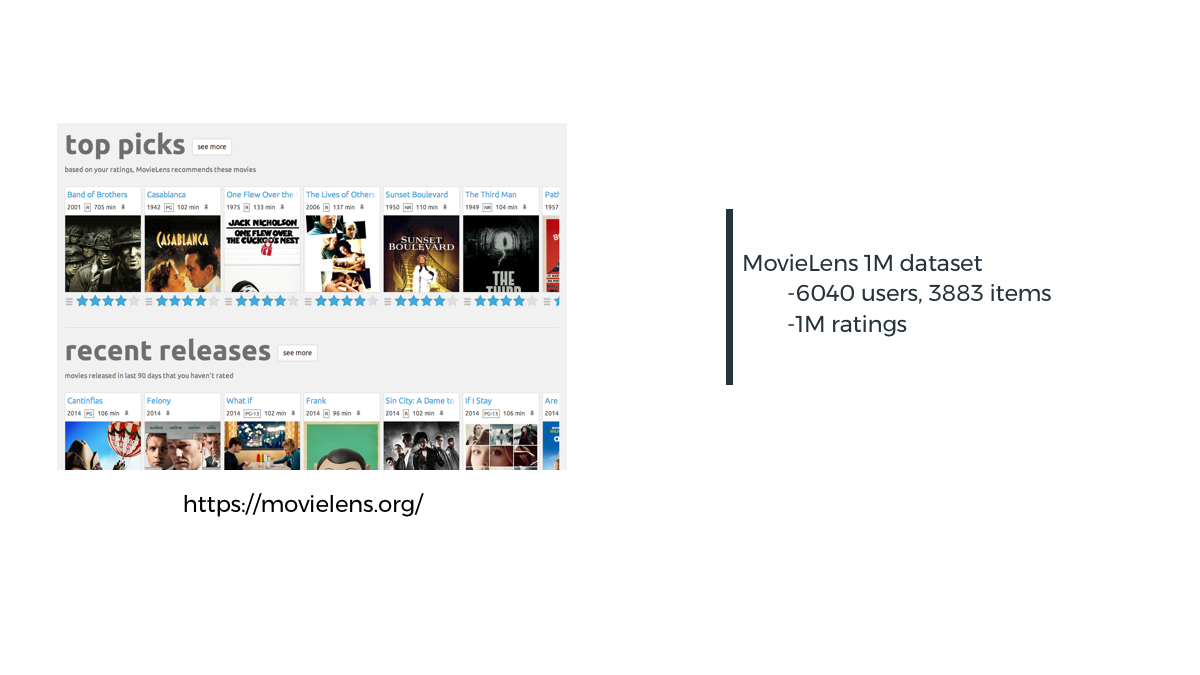
Home
Problem
Solution
Demo
Result
Algorithms
Matrix Factorization-SGD
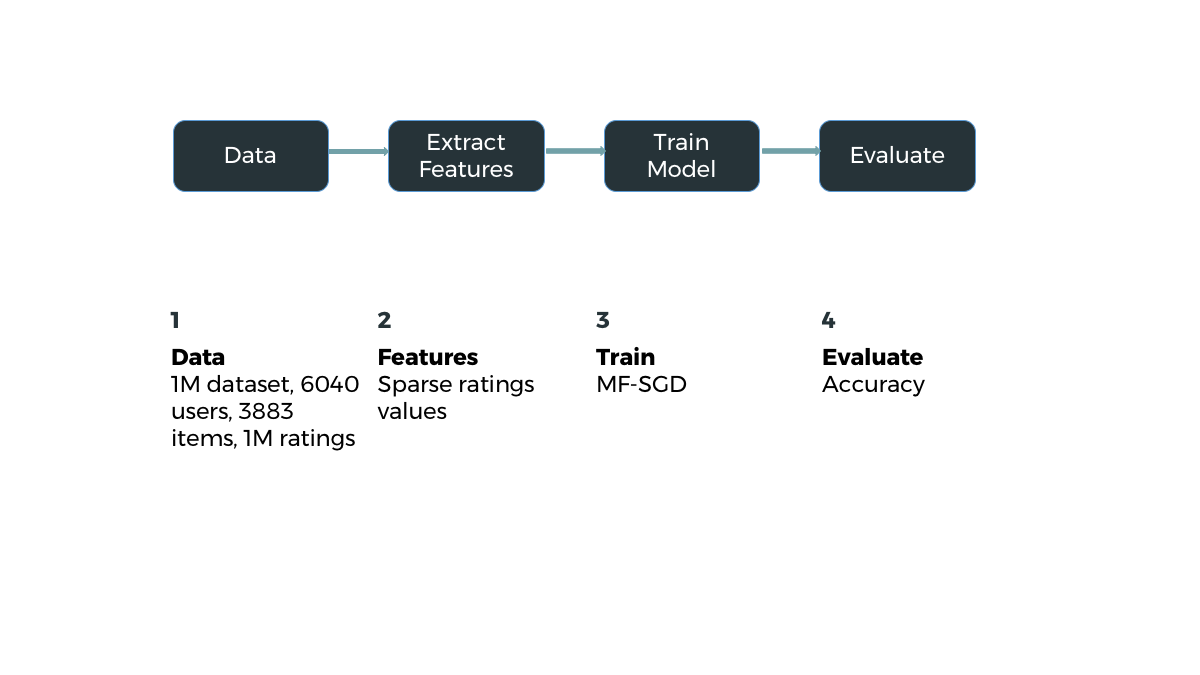
Home
Problem
Solution
Demo
Result
Algorithms
Matrix Factorization-SGD
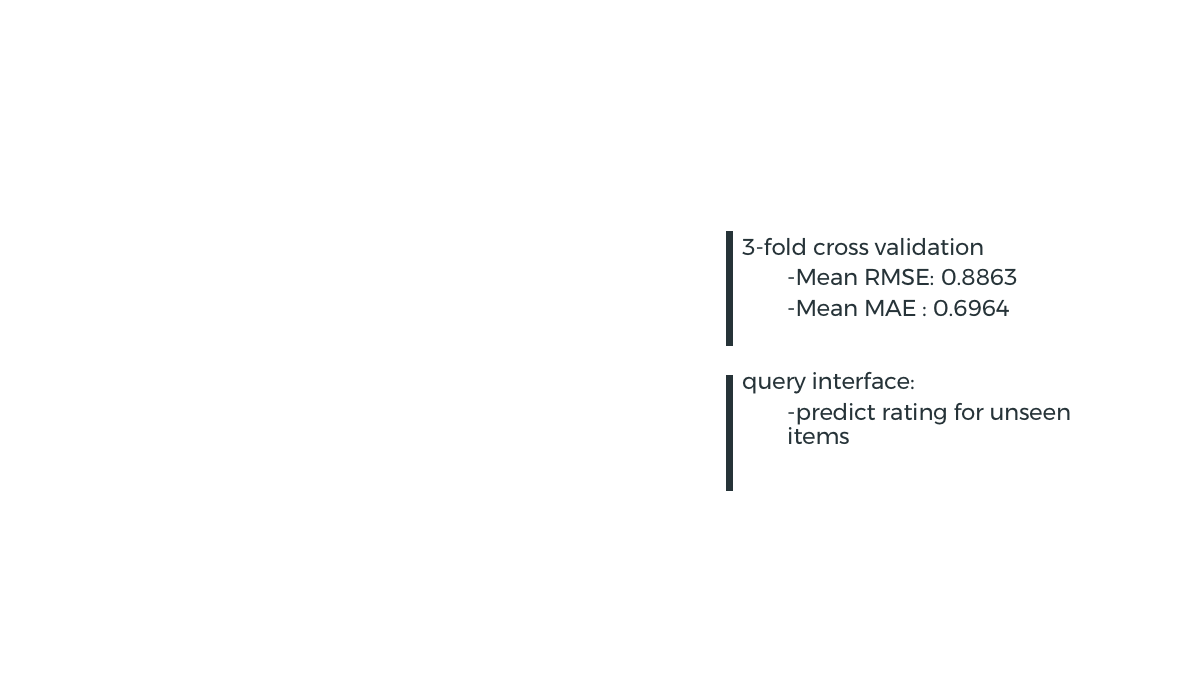
Principal Component Analysis PCA
K-Means
Alternating Least Squares

Algorithms
Home
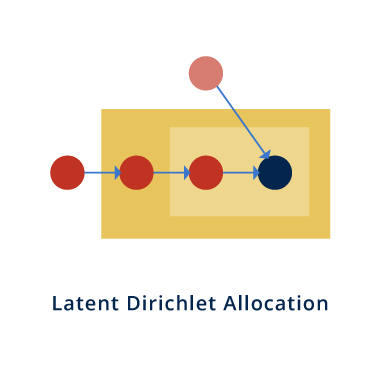
Latent Dirichlet Allocation
Matrix Factorization-SGD
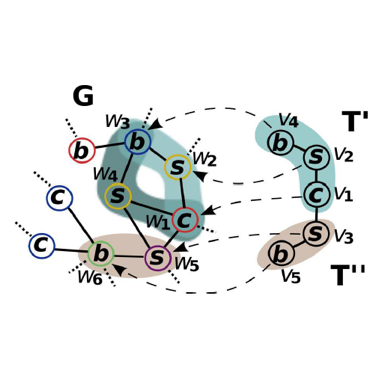
Subgraph Counting
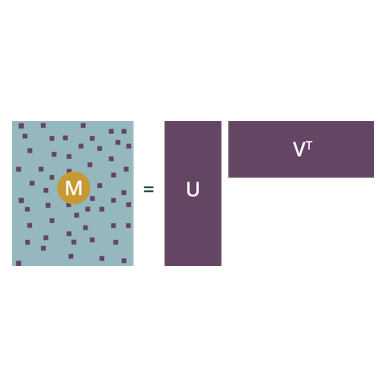
Principle Component Analysis (PCA)
Home
Overview
Mechanism
Performance
Back
Principle Component Analysis (PCA) is a widely used statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components (or sometimes, principal modes of variation).
Principle Component Analysis (PCA)
Home
Overview
Mechanism
Performance
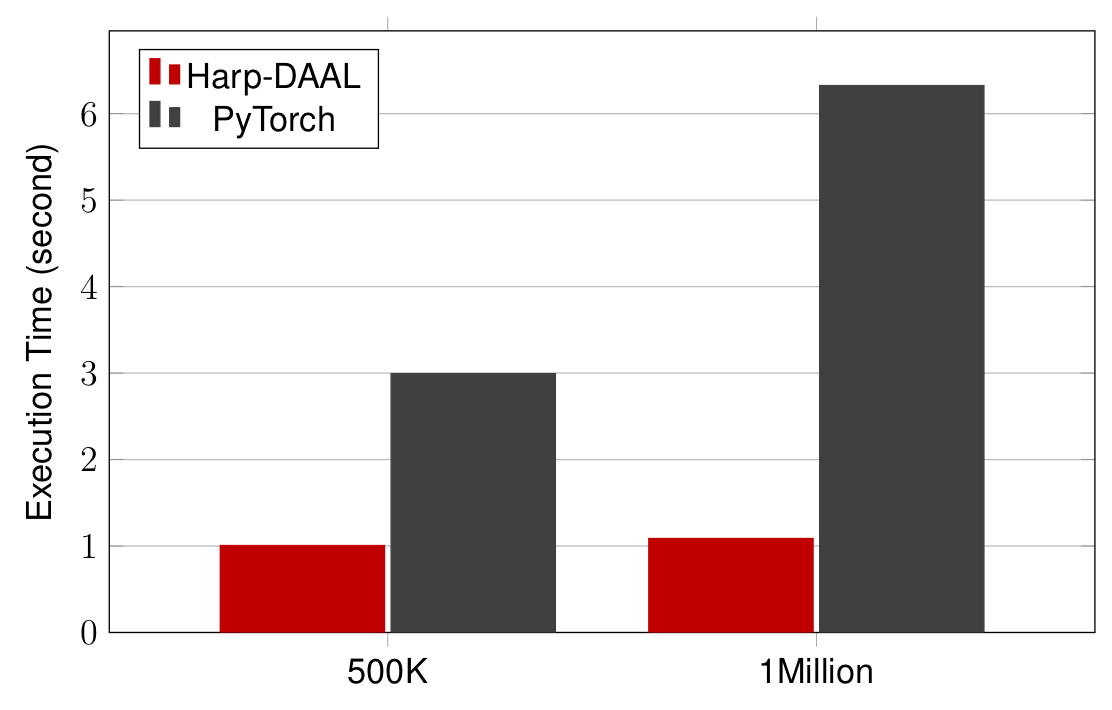
-
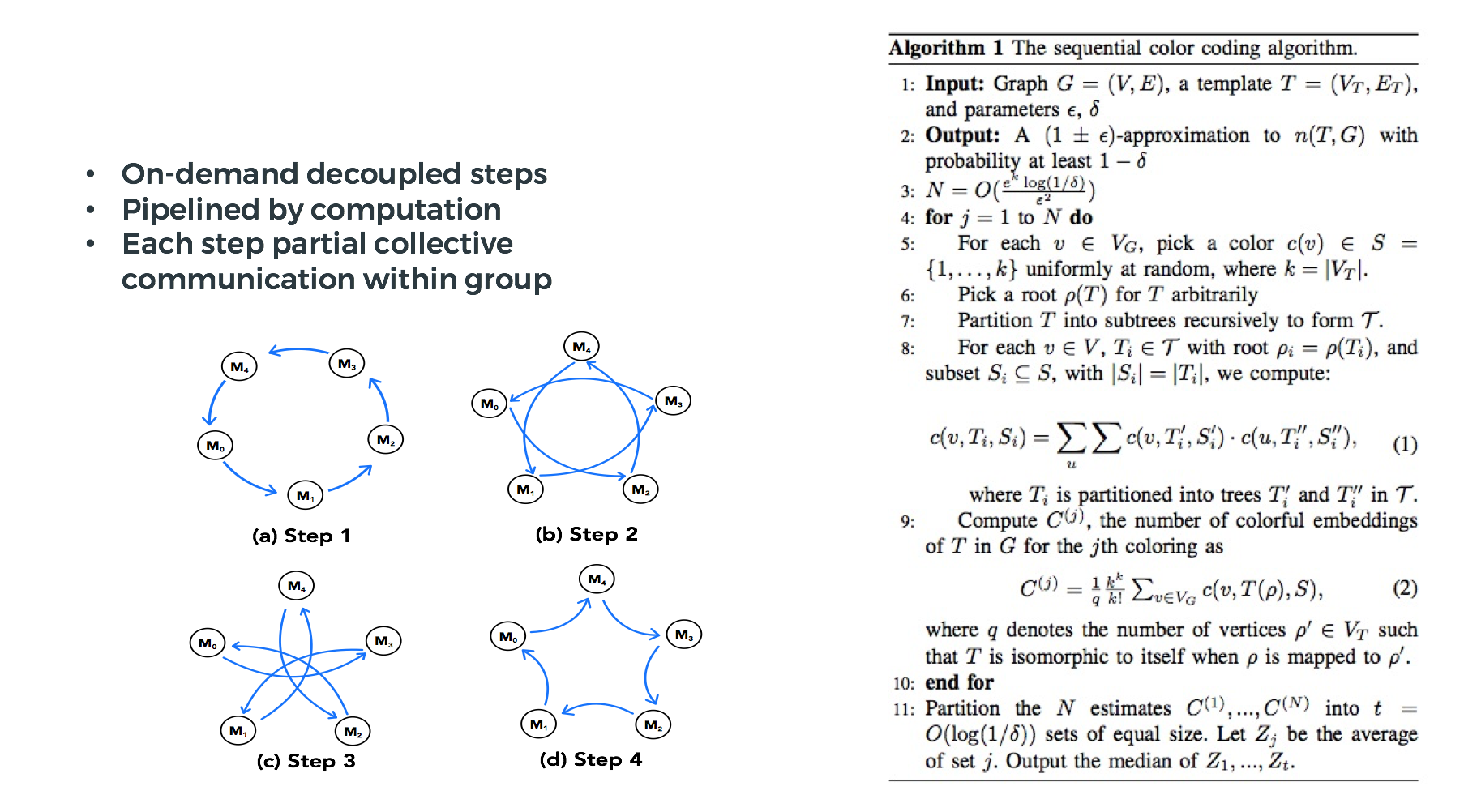
Datasets: 500K or 1 million data points of feature dimension 300
-
Running on single KNL 7250 (Harp-DAAL) vs. single K80 GPU (PyTorch)
-
Harp-DAAL achieves 3x to 6x speedups
Back
Principle Component Analysis (PCA)
Home
Overview
Mechanism
Performance
-
Synchronization: the partial results on each local node are sent to the master node for final computations using
-
Vectorization: computation is transformed into BLAS-level 3 matrix-matrix operations
allreduce
Back
K means
Home
Overview
Mechanism
Performance
-
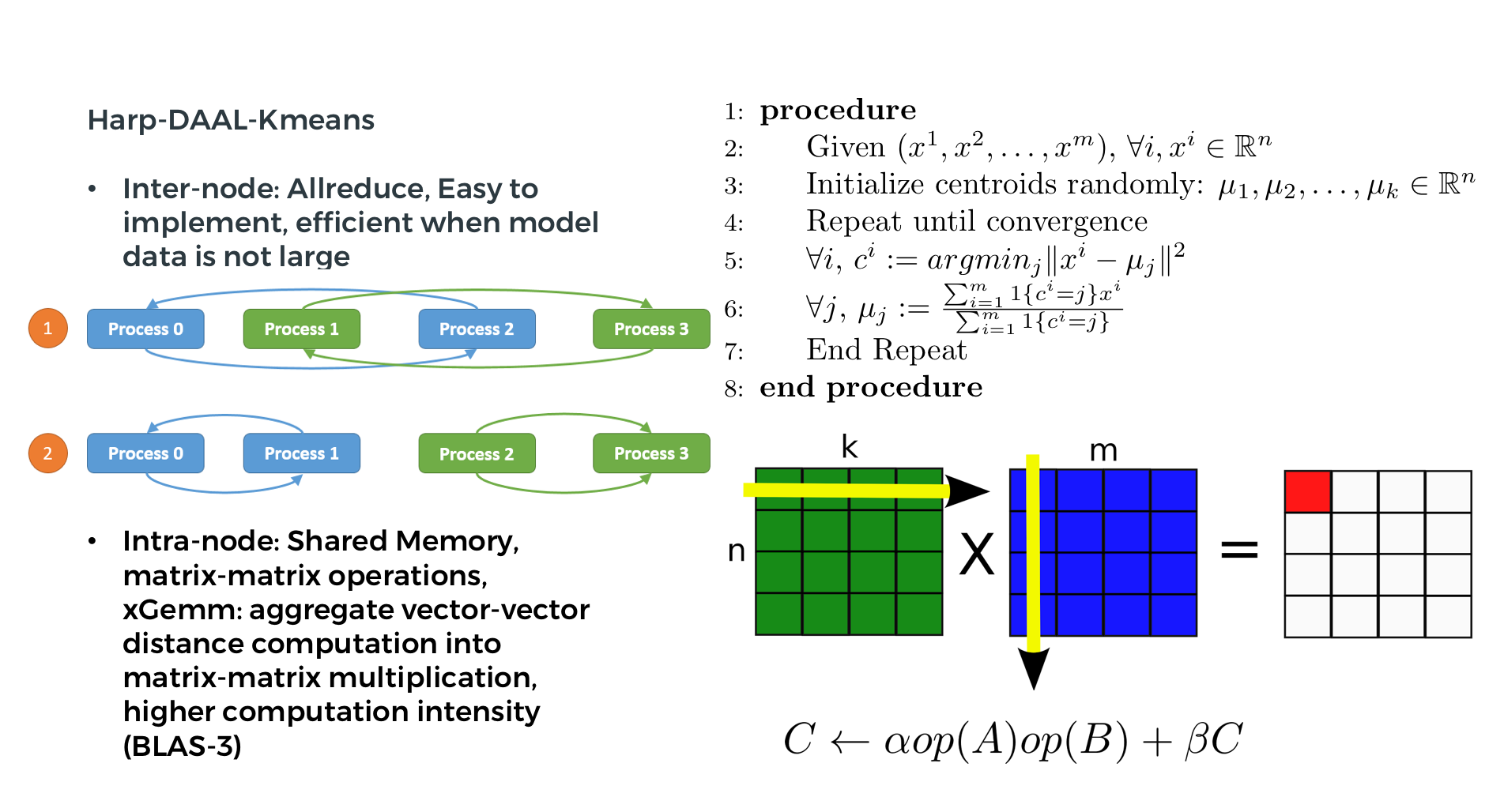
K-means is a widely used clustering algorithm in machine learning community.
-
It iteratively computes the distance between each training point to every centroids, reassigns the training point to new cluster and recompute the new centroid of each cluster.
Computation
Back
K means
Home
Overview
Mechanism
Performance
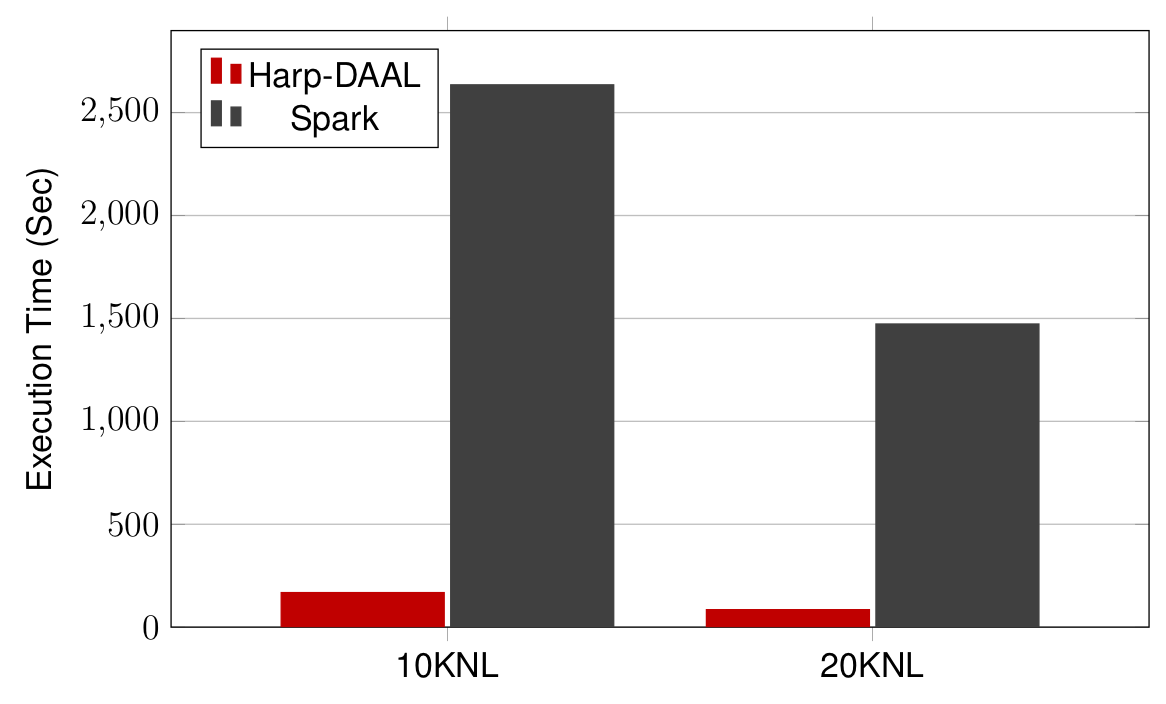
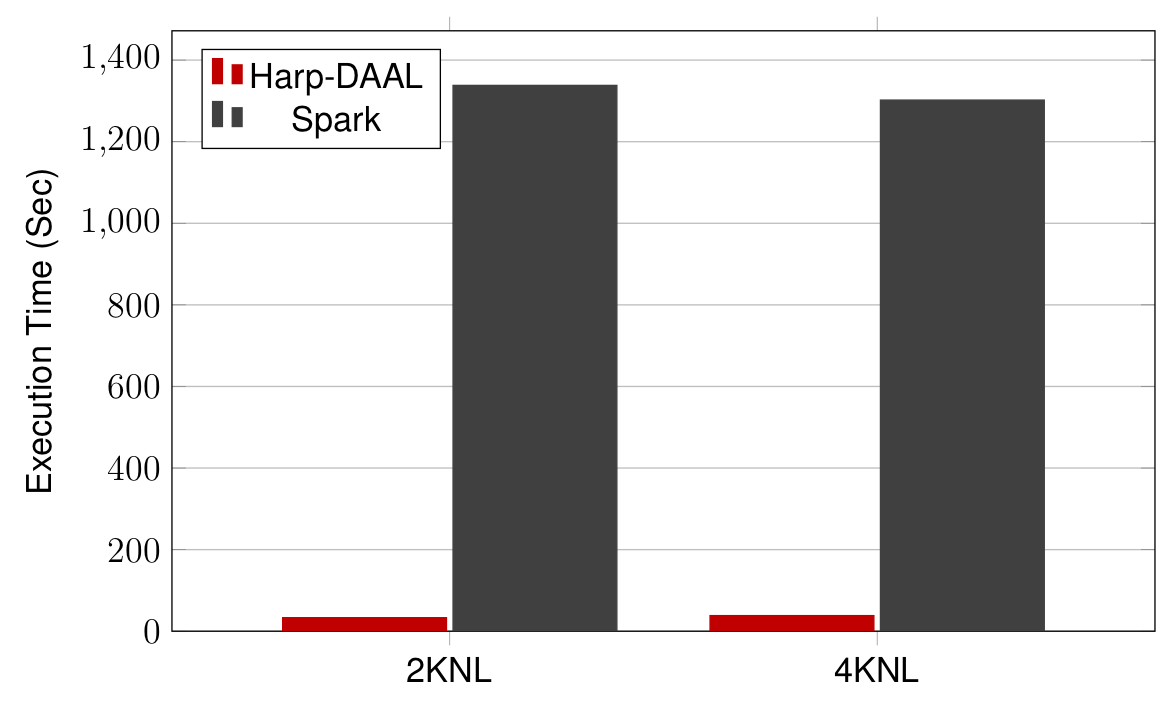
-
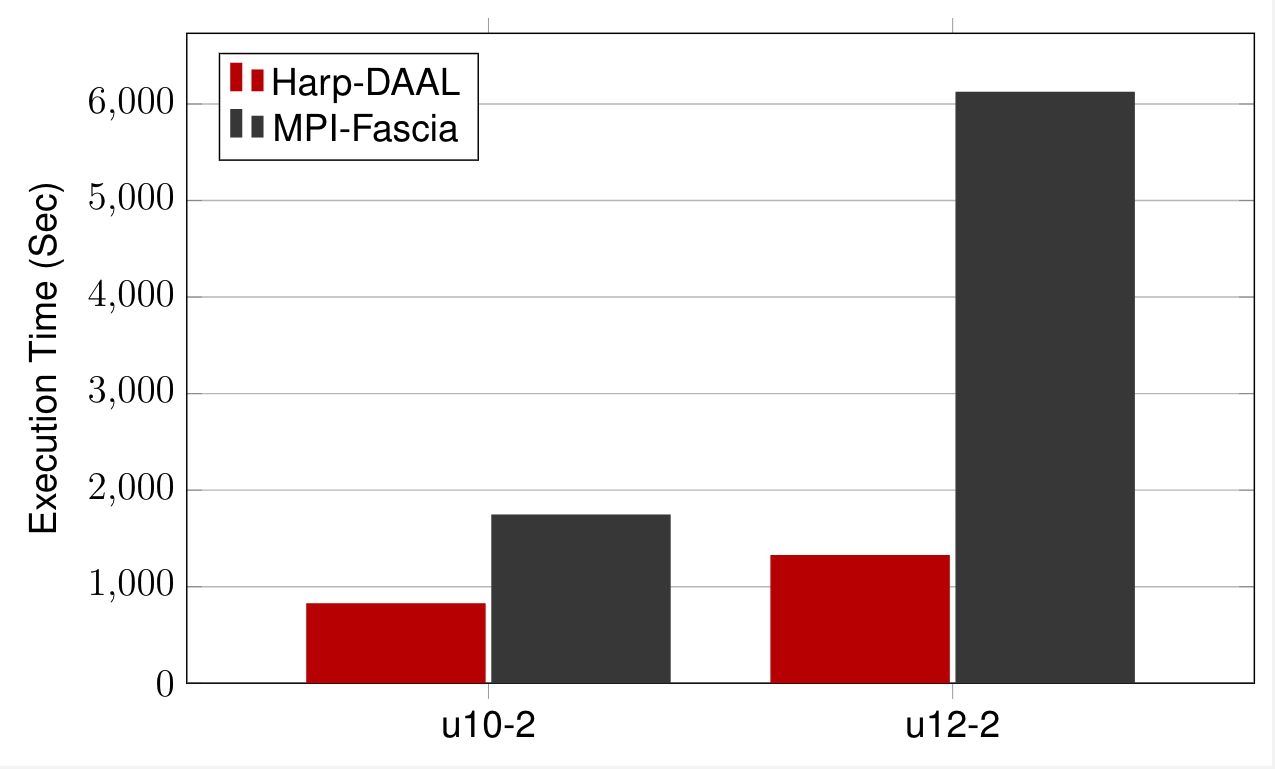
Datasets: 5 million points, 10 thousand centroids, 100 feature dimensions
-
10 to 20 Intel KNL7250 processors
-
Harp-DAAL has 15x speedups over Spark MLlib
Computation
Back
K means
Home
Overview
Mechanism
Performance
-
Synchronization: uses a and another to synchronize model data, i.e. centroids
-
Vectorization: computation of point-centroid distance is transformed into BLAS-level 3 matrix-matrix operations
regroup
allgather
Computation
Back
K means
Home
Overview
Mechanism
Performance
Computation
Back
ALS
Home
Overview
Mechanism
Performance
-
When using a Matrix Factorization approach to implement a recommendation algorithm you decompose your large user/item matrix into lower dimensional user factors and item factors.
-
Alternating Least Squares (ALS) is one widely used approach to solve this optimization problem. The key insight is that ALS fixes each one of those factors alternatively. When one is fixed, the other one is computed, and vice versa.
Computation
Back
ALS
Home
Overview
Mechanism
Performance
-
Dataset, Yahoomusic, with 250 million training points, factor dimension 100
-
Running on KNL 7250 processors
-
Harp-DAAL achieves around 40x speedups over Spark-MLlib
Computation
Back
ALS
Home
Overview
Mechanism
Performance
-
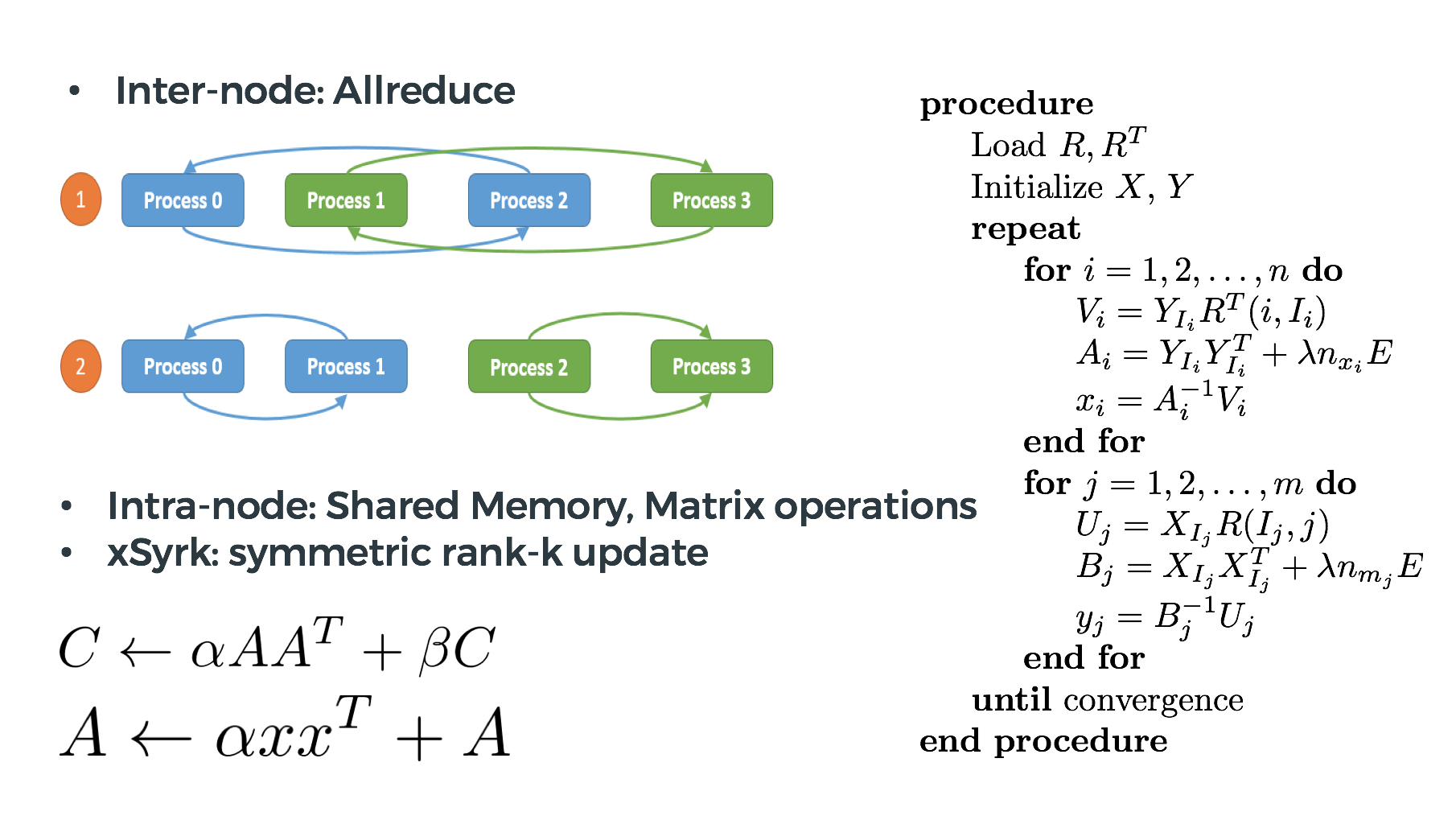
Synchronization: usersPartition and itemsPartition demand a synchronization among mappers, where we use
operation.
-
Vectorization: computation is transformed into BLAS-level 3 matrix-matrix operations
allgather
Computation
Back
ALS
Home
Overview
Mechanism
Performance
Computation
Back
Latent Dirichlet Allocation (LDA)
Home
Overview
Mechanism
Performance
-
Latent Dirichlet Allocation(LDA) is a topic modeling technique to discover latent structures inside data.
-
The training algorithm, Collapsed Gibbs Sampling, goes through each token in the data collection, reassign a new topic to it by sampling from a multinomial distribution of a conditional probability which depends on current status of word-topic and doc-topic counts, and then update the counts until converges.
Back
Home
Overview
Mechanism
Performance
-
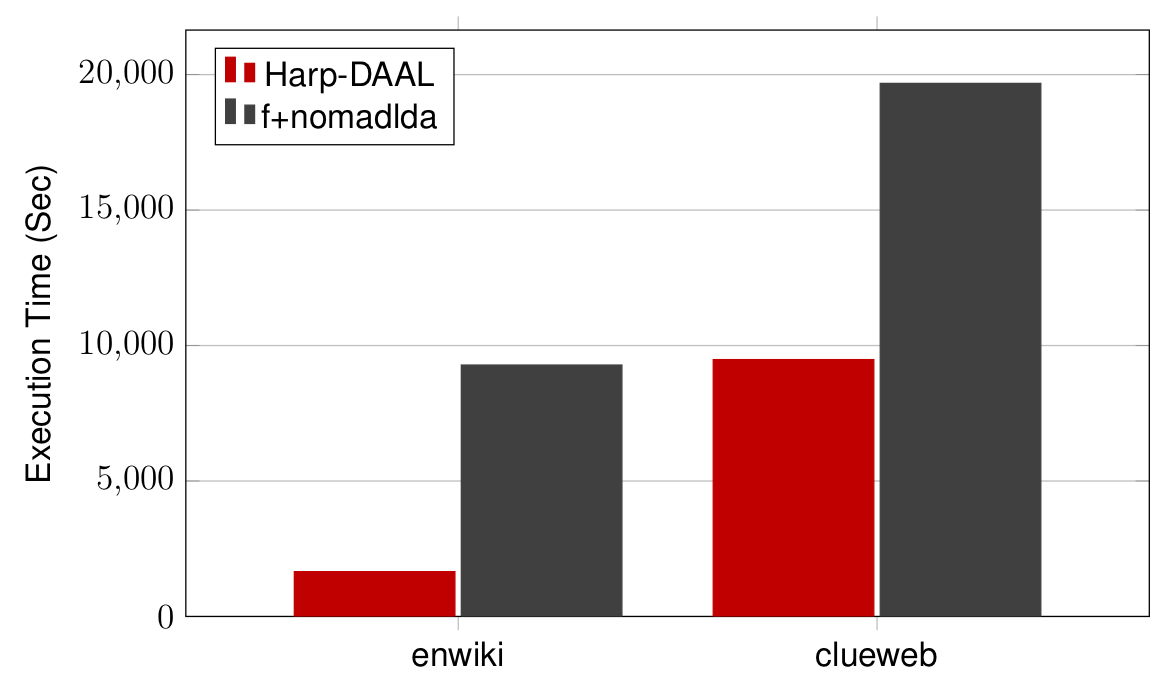
Dataset: Enwiki 3.7 Million docs, 20 Million vocabulary, 1.6 Billion tokens; Clueweb: 76 Million docs, 1 Million vocabulary, 29 Billion tokens
-
8 Xeon E5 for Enwiki, 40 Xeon E5 for Clueweb
-
Harp solution achieves 2x to 5x speedups over state-of-the-art c/c++ solution
Latent Dirichlet Allocation (LDA)
Back
Home
Overview
Mechanism
Performance
-
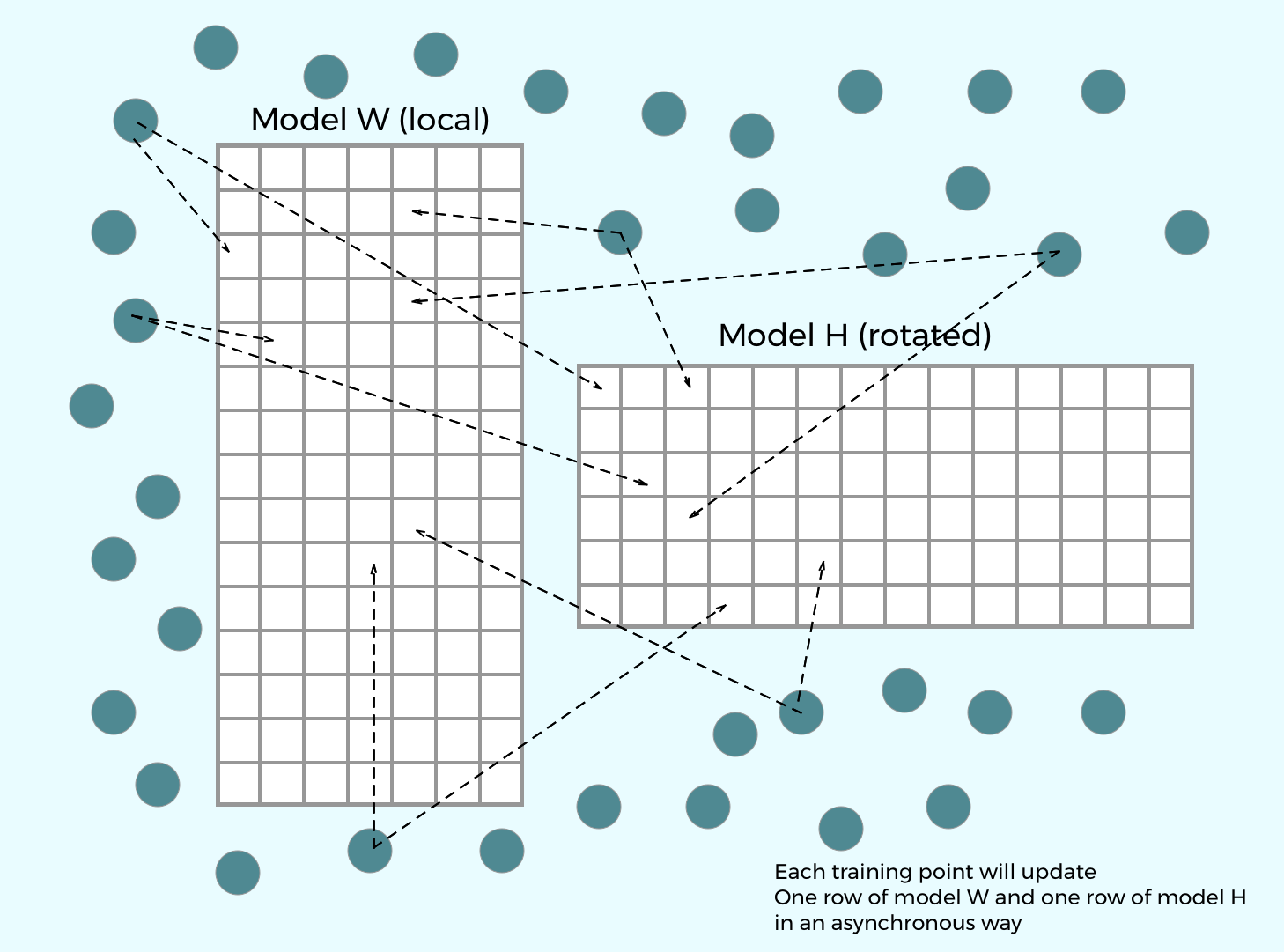
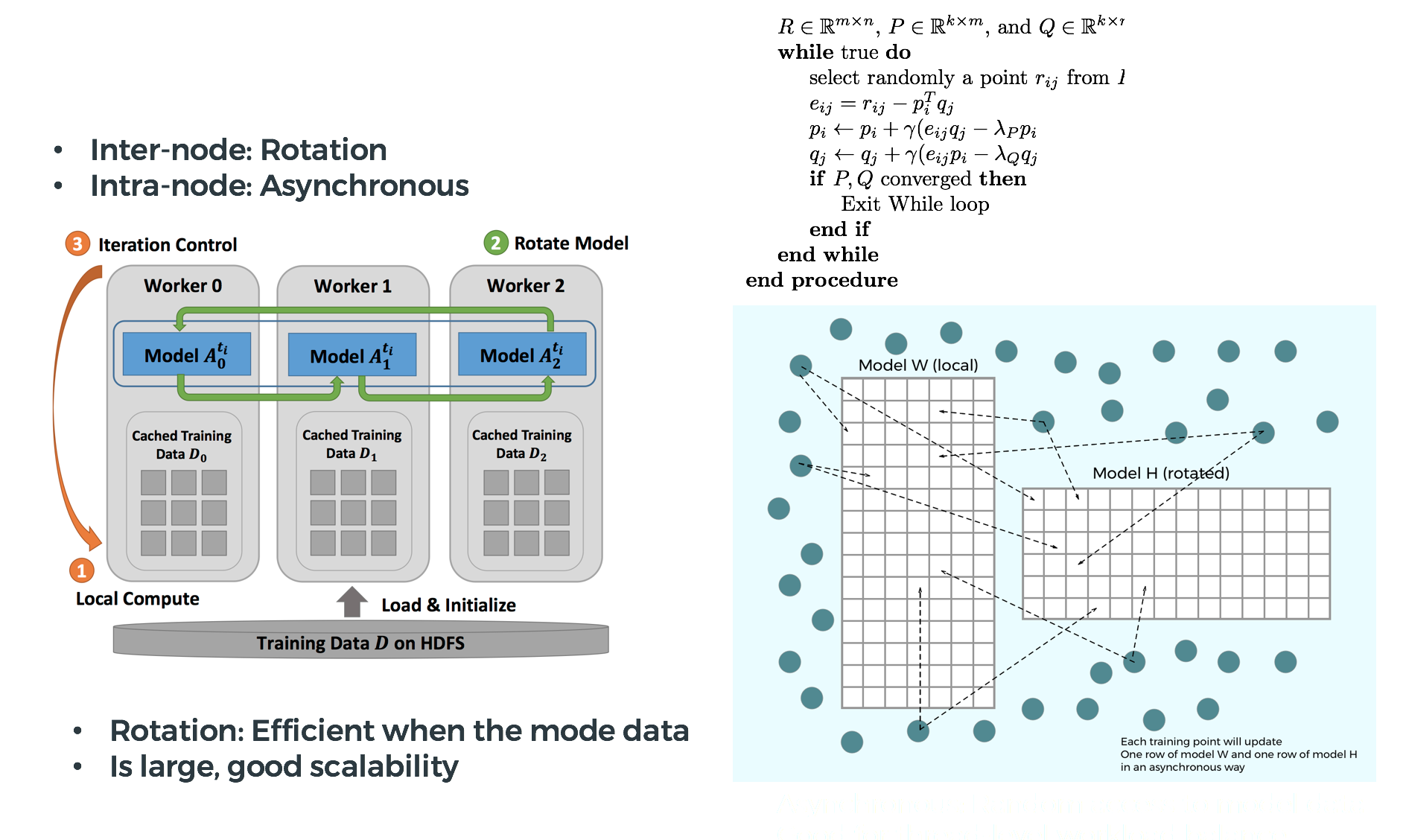
Synchronization:
-
Distributed model
-
A scheduler maintains a dynamic order of model parameter updates and to avoid the update conflict.
-
is used for synchronization.
-
Rotation
Latent Dirichlet Allocation (LDA)
-
Vectorization: no
-
Memory:
-
block based task scheduling to reduce the pressure of random memory access
-
Back
Matrix Factorization- SGD
Home
Overview
Mechanism
Performance
-
When using a Matrix Factorization approach to implement a recommendation algorithm you decompose your large user/item matrix into lower dimensional user factors and item factors.
-
A standard stochastic gradient descent(SGD) procedure will update the model of user factors and item factors while iterating over each training data point.
Computation
Back
Home
Overview
Mechanism
Performance
-
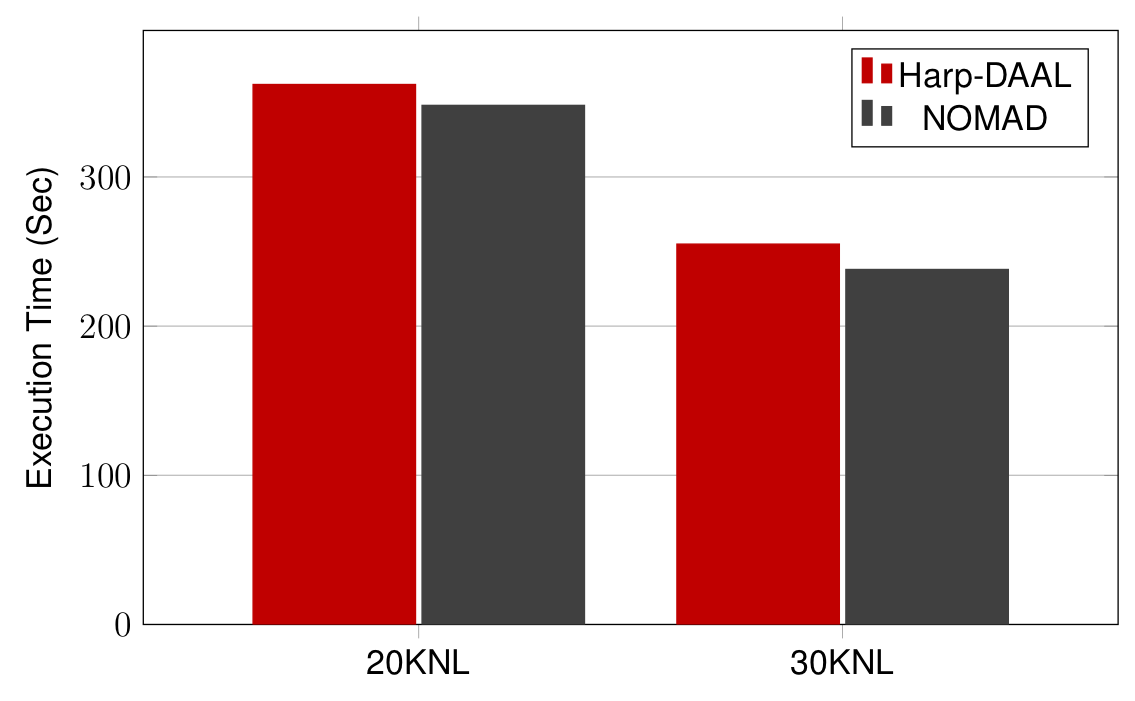
Datasets: Clueweb with 1.5 billion points, factor dimension 2000
-
20 to 30 Intel KNL7250 processors
-
Harp-DAAL has comparable performance to state-of-the-art C/C++ MPI solution NOMAD
Computation
Matrix Factorization- SGD
Back
Home
Overview
Mechanism
Performance
-
synchronization:
-
Distributed model
-
A scheduler maintains a dynamic order of model parameter updates and to avoid the update conflict.
-
is used for synchronization.
-
-
Vectorization:
-
BLAS-level 1 for dense vector operation
-
-
Memory
-
random memory access
-
Rotation
Computation
Matrix Factorization- SGD
Back
Home
Overview
Mechanism
Performance
Computation
Matrix Factorization- SGD
Back
SubGraphCounting
Home
Overview
Mechanism
Performance
• Subgraph counting refers to the process of finding occurrences of a template T within a graph G. In Harp-DAAL, subgraph counting uses a color coding algorithm to find large tree-like templates from extreme large graph dataset.
• Color coding is a randomized approximation algorithm , which gives the estimation of the number of embeddings of trees of size k in O(𝑐 𝑝𝑜𝑙𝑦 𝑛 ) time for a constant c.
• A Dynamic programming method is adopted to decompose tree-like templates into a group of sub-templates and count them in a bottomup way.
Computation
Back
K
Home
Overview
Mechanism
Performance
-
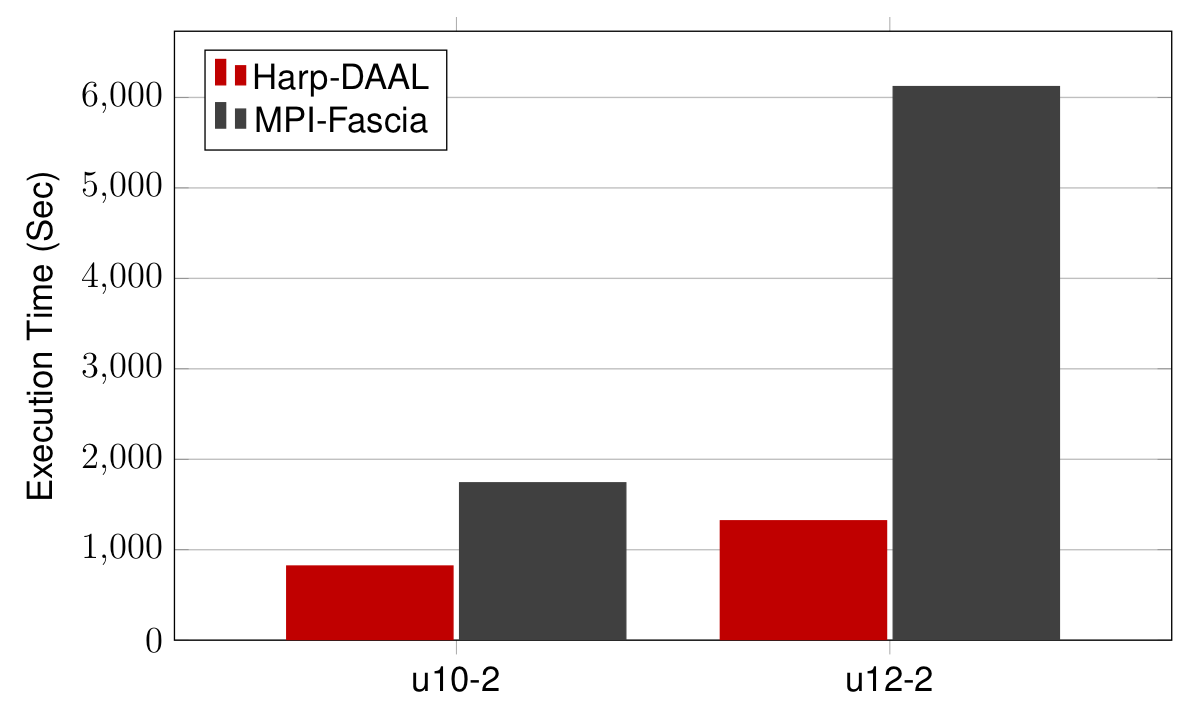
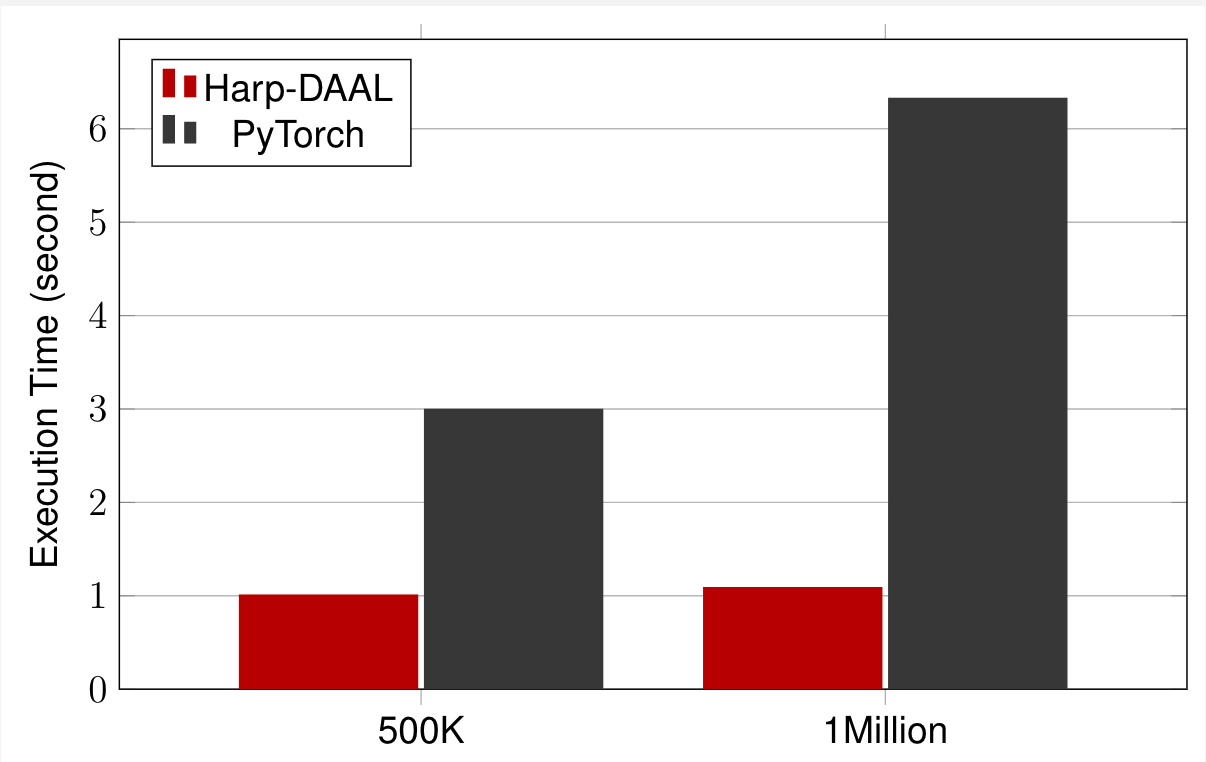
Datasets: Twitter with 44 million vertices, 2 billion edges
-
25 Intel Xeon E5 2670
-
Harp-DAAL has 2x to 5x speedups over state-of-the-art MPI-Fascia solution
Computation
SubGraphCounting
Back
Home
Overview
Mechanism
Performance
Adaptive Group
Computation
SubGraphCounting
-
Synchronization:
-
Distributed model
-
-
-
Vectorization:
-
no
-
-
Memory
-
compact data structure, and data compression
-
Back
Home
Overview
Mechanism
Performance
Computation
SubGraphCounting
Back
Performance Comparison
Home
Kmeans
PCA
Subgraph
Datasets: 5 million points, 10 thousand centroids, 10 feature dimensions
10 to 20 Intel KNL7250 processors
Harp-DAAL has 15x speedups over Spark MLlib
Datasets: 500K or 1 million data points of feature dimension 300
Running on single KNL 7250 (Harp-DAAL) vs. single K80 GPU (PyTorch)
Harp-DAAL achieves 3x to 6x speedups
-
Datasets: Twitter with 44 million vertices, 2 billion edges
-
25 Intel Xeon E5 2670
-
Harp-DAAL has 2x to 5x speedups over state-of-the-art MPI-Fascia solution
Computation Model
Back
Home
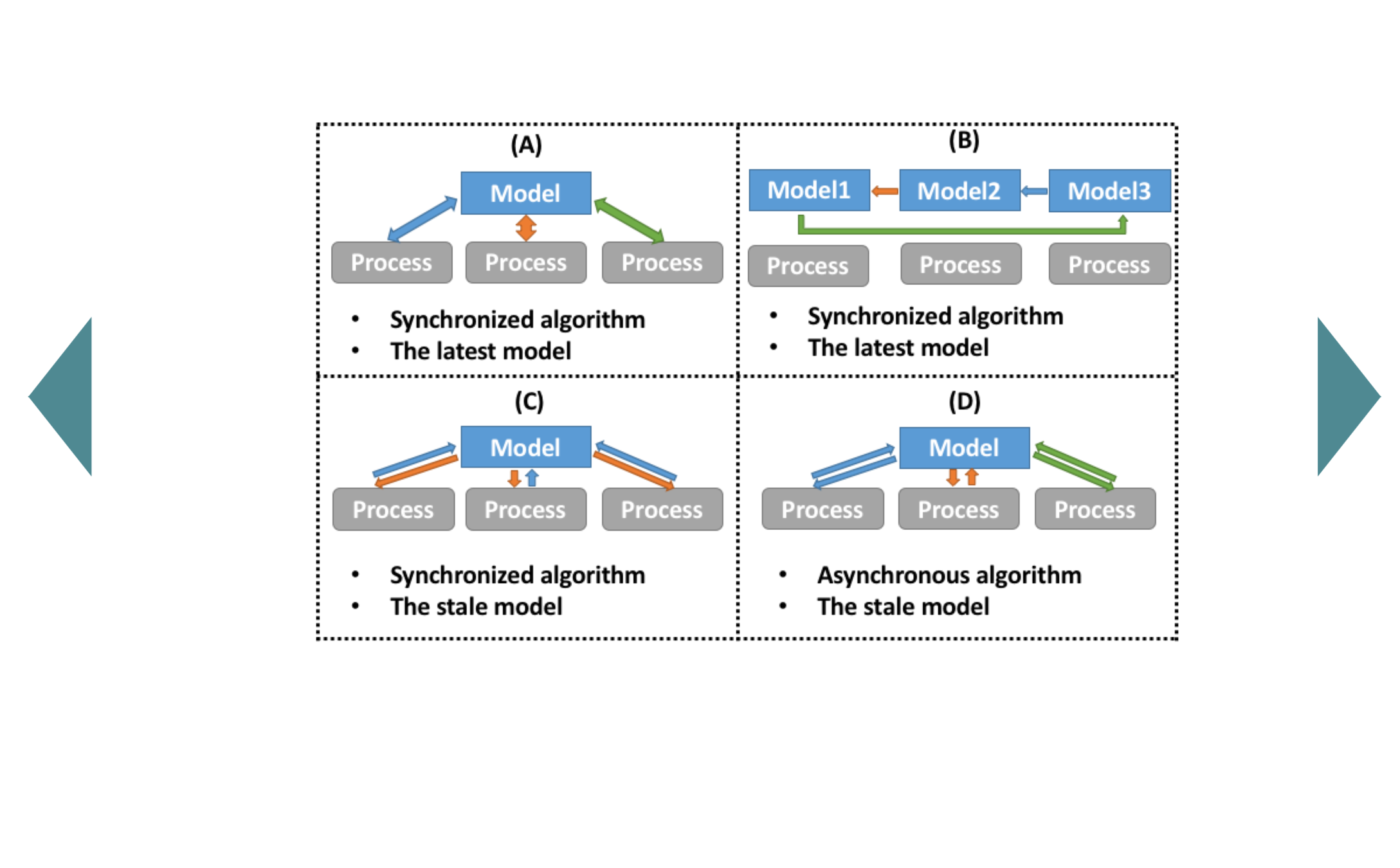
Harp Computation Models
Inter-node & Intra-node
Back
Home
Computation Model

Harp Computing Models
Intra-node (Process)
Back
Home
Computation Model

Intra-node
Schedulers (Thread)
Back
Home
Computation Model
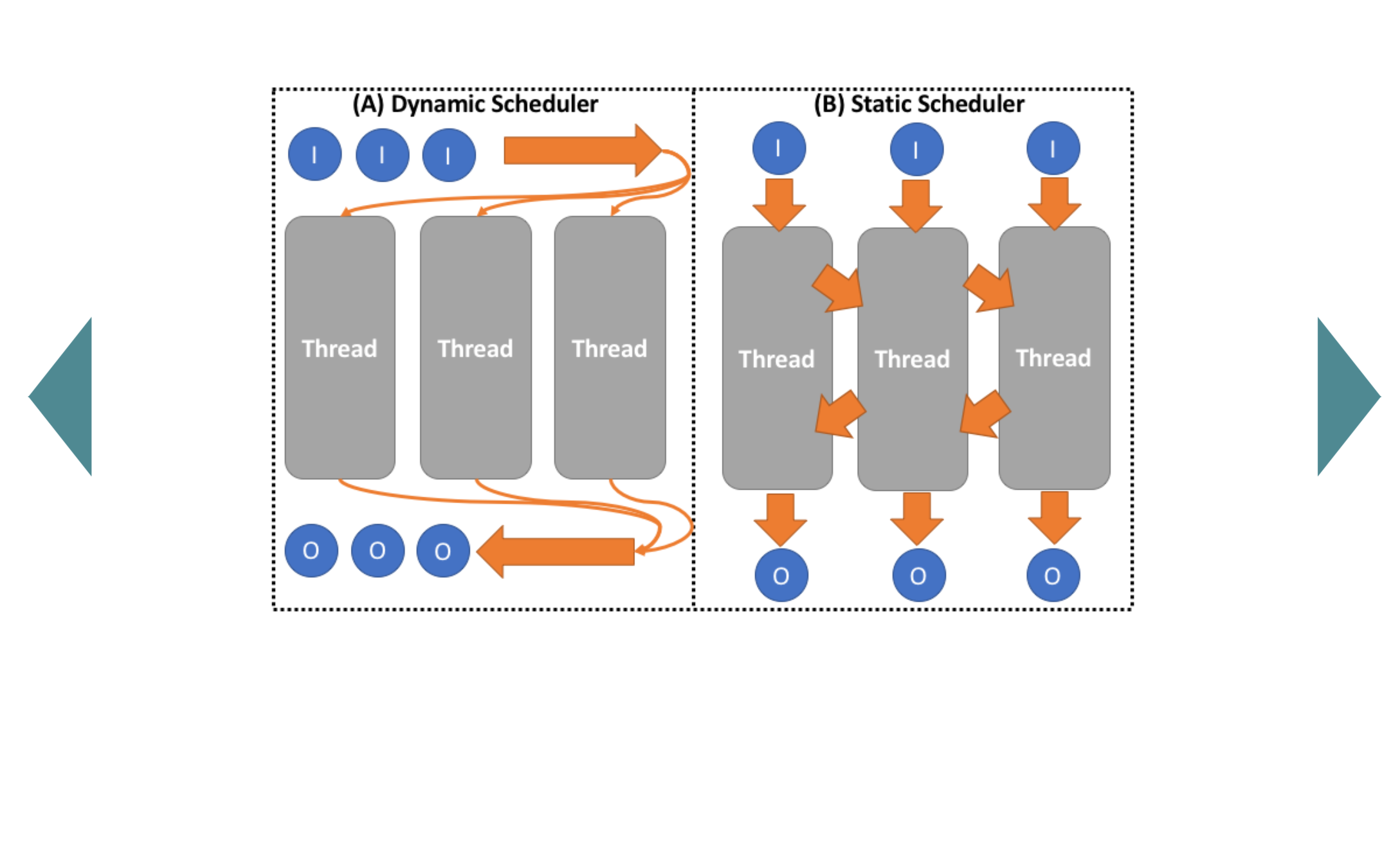
Schedule Training Data Partitions to Threads
(only Data Partitions in Computation Model A, C, D; Data and/or Model Partitions in B)
Collective Communication
Home
Back
Broadcast
Reduce
allgather
allreduce
regroup
Push and Pull
rotate
Home
Back
Broadcast
Reduce
allgather
allreduce
regroup
rotate
Push and Pull
Collective Communication
Home
Back
Broadcast
Reduce
allgather
allreduce
regroup
rotate
Push and Pull
Collective Communication
Home
Back
Broadcast
Reduce
allgather
allreduce
regroup
rotate
Push and Pull
Collective Communication
Home
Back
Broadcast
Reduce
allgather
allreduce
regroup
rotate
Push and Pull
Collective Communication
Home
Back
Broadcast
Reduce
allgather
allreduce
regroup
rotate
Push and Pull
Collective Communication
Home
Back
Broadcast
Reduce
allgather
allreduce
regroup
rotate
Push and Pull
Collective Communication
Hands On
Home
K-means
Naive Bayes
MF-SGD
Algorithms
Python
K-means
Home
Problem
Procedure
Demo
Code Instructions

Back
K-means
Home
Problem
Procedure
Demo
Code Instructions
Back
K-means
Home
Problem
Procedure
Demo
Code Instructions
Back
K-means
Home
Problem
Procedure
Demo
Code Instructions
Back
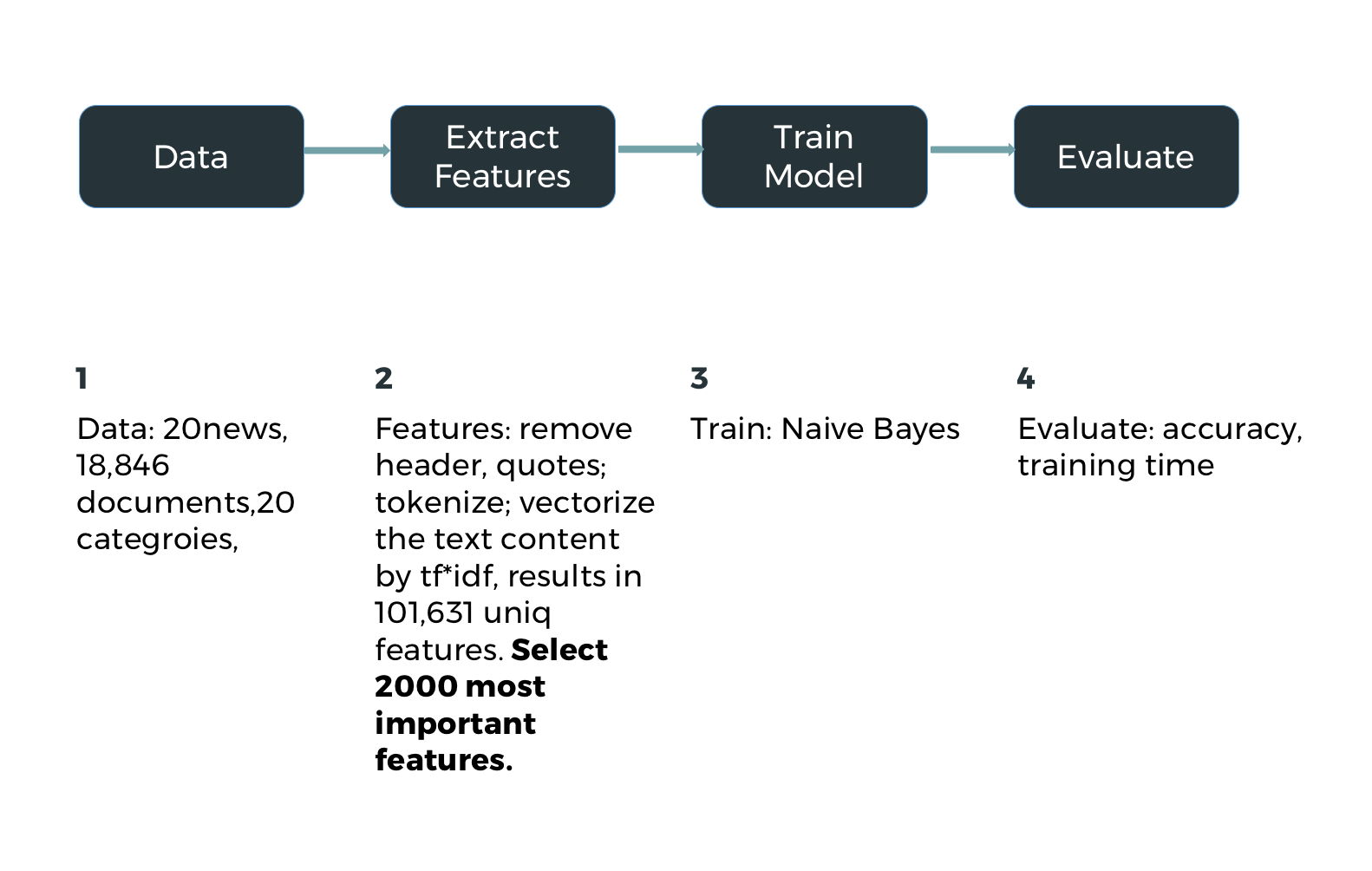
Naive Bayes
Home
Problem
Procedure
Demo
Code Instructions
Back
Home
Problem
Procedure
Demo
Code Instructions
Naive Bayes
Back
Home
Problem
Procedure
Demo
Code Instructions
Naive Bayes
Back
Home
Problem
Procedure
Demo
Code Instructions
Naive Bayes
Back
Recommender System (MF-SGD)
Home
Problem
Procedure
Demo
Code Instructions
Back

Home
Problem
Procedure
Demo
Code Instructions
Recommender System (MF-SGD)
Back
Home
Problem
Procedure
Demo
Code Instructions
Recommender System (MF-SGD)
Back
Home
Problem
Procedure
Demo
Code Instructions
Recommender System (MF-SGD)
Back
Back
Home
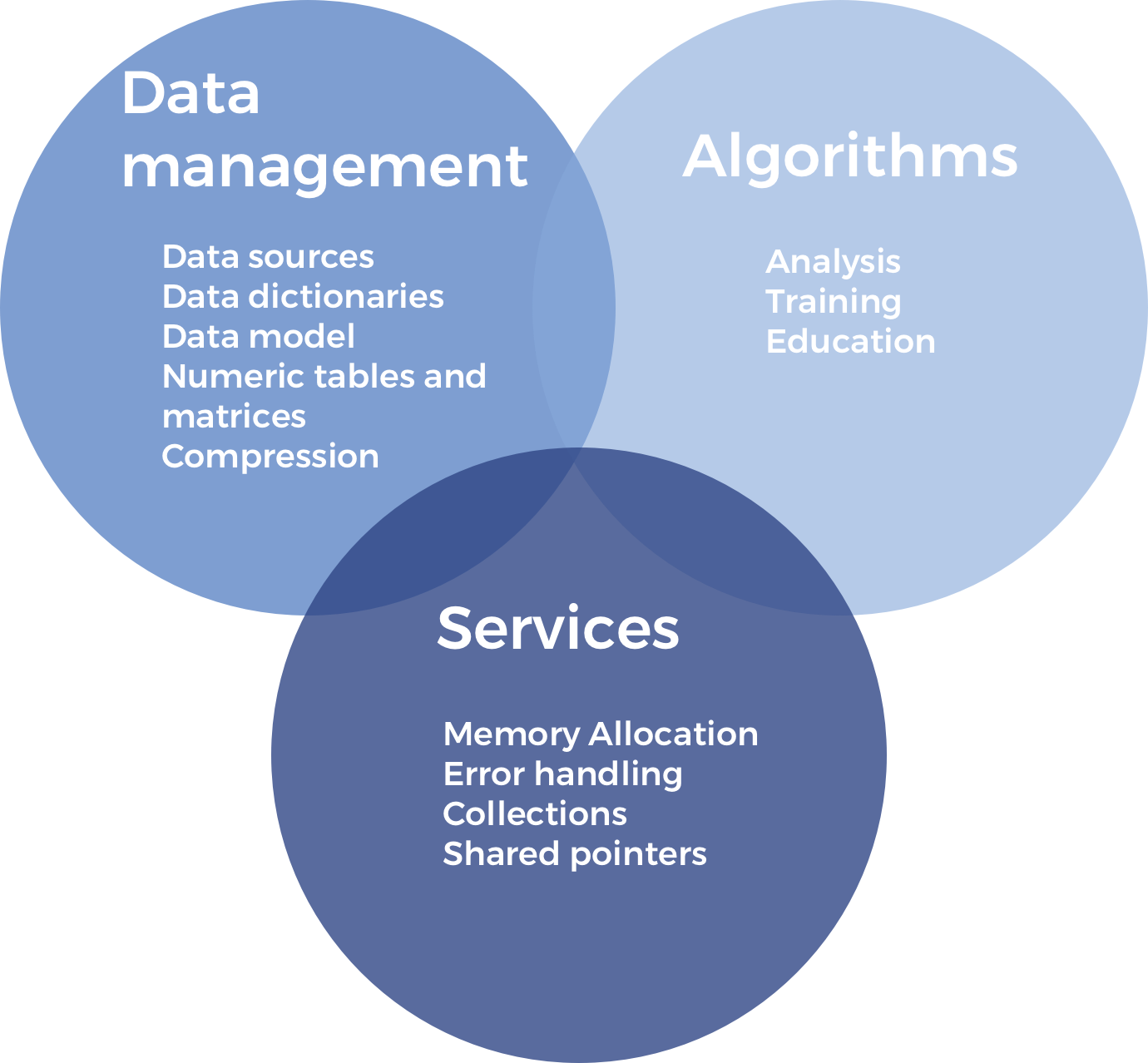
Intel® DAAL is an open-source project that provides:
Algorithms Kernels to Users
Batch Mode (Single Node)
Distributed Mode (multi nodes)
Streaming Mode (single node)
Data Management & APIs to Developers
Data structure, e.g., Table, Map, etc.
HPC Kernels and Tools: MKL,TBB, etc.
Hardware Support: Compiler
Intel® Data Analytics Acceleration Library (Intel® DAAL)
Back
Home
ML Applications
Data Analysis
Harp-Computation-Model
Big Model
Data
Big Training
Data
Big Model
Data
Harp-Communication
DAAL Kernels: MF-SGD, K-means, LDA
HPC Kernels: BLAS, MKL, TBB, OpenMP
HPC Hardware Platforms: Haswell CPU, KNL Xeon Phi
HPC
Big Data
Back
Home